控制爱莎公主的走位,躲避来自火王子的攻击,w向上、s向下、a向左、d向右,加速按住shift键。看看谁的积分更高!
1.0版本上线!可以在手机和平板上玩哦。
美术制作:萱萱
人物设计:萱萱
故事情节:萱萱
程序设计:萱萱爸爸
控制爱莎公主的走位,躲避来自火王子的攻击,w向上、s向下、a向左、d向右,加速按住shift键。看看谁的积分更高!
1.0版本上线!可以在手机和平板上玩哦。
美术制作:萱萱
人物设计:萱萱
故事情节:萱萱
程序设计:萱萱爸爸
ArcGis提供了非常便捷的模型构建器,可以将简单的工具步骤组合起来,加入简单的代码后,就能组合形成能完成比较复杂任务的工具。
按照教程,一个初学者可能就能很快的利用cad道路网和地块信息来制作一张用地规划图。但大部分教程中不包含完善的道路网本身的批量化生成和制作。而我就更喜欢研究这类不在任何教程中出现的内容,这才能体现研究的价值。
这次展示的是我设计的利用ArcGis模型构建器设计的“三维日照分析”工具。在分析方面没有问题,但运行时间上还有很大空间。
上面提到的道路中线批量自动转路网(路口倒角)的工具,以后我将分享。
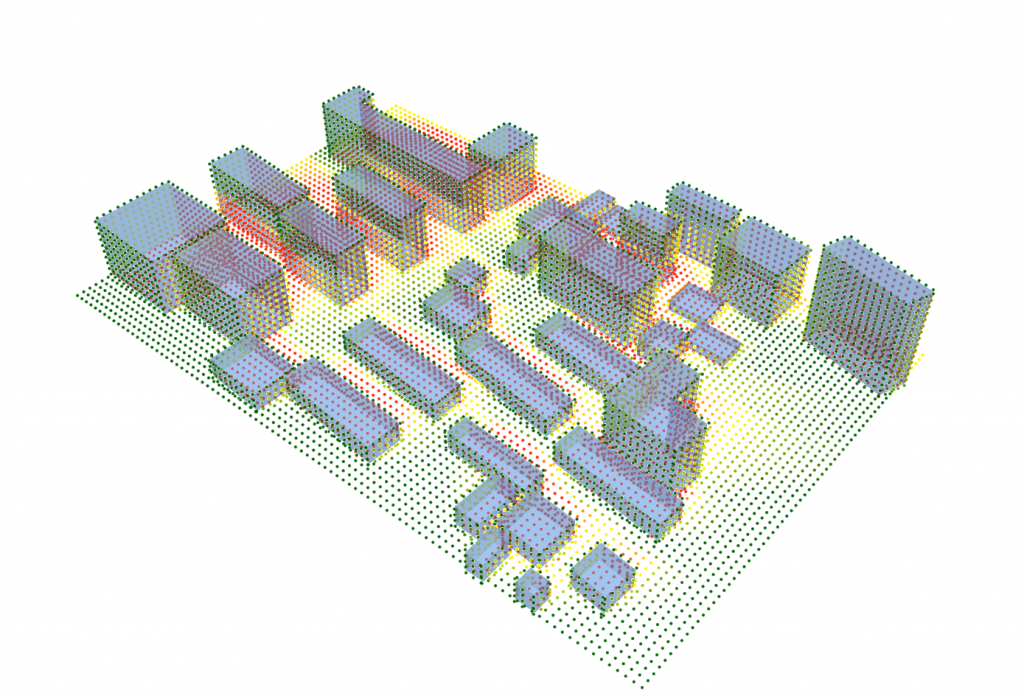


ArcGis地图服务是比较常用的一种在线地理信息共享发布的方式,一般通过网络浏览器进行访问,可以看到地图、查询等服务,但这些服务内容显然难以满足专业的规划设计工作者。
我编写的地图服务爬取代码,利用python的requests库对用户指定的ArcGis地图服务网站进行访问,可以将原始的EsriJson数据分门别类、统一下载。比较利用Qgis,更适合大批量成系统的数据获取工作。
请注意,爬取数据前应获得相应权限。
import json,requests,os,shutil
import pandas as pd
#???为需要爬取的网站
head={'Connection': 'keep-alive', 'Origin': 'http://???', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36', 'Accept': '*/*', 'Referer': 'http://???', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9'}
alllisturl = '???/js/menu.js'
#地图网站访问url格式
querynumurl = 'http://???/arcgis/rest/services/?/?/MapServer/1/query?f=json&where=1=1&returnIdsOnly=true'
querydetailurl =' http://???/arcgis/rest/services/?/?/MapServer/1/query?f=json&objectIds=624,625,626,627,628,629,630,631&inSR&outSR&returnGeometry=true&outFields=*&returnM=true&returnZ=true'
def getname(a):
temp=[]
if type(a)==list:
for b in a:
temp += [getname(b)]
if type(a)==dict:
if 'nodes' in a.keys():
temp = [a['TEXT'],getname(a['nodes'])]
else:
temp = [a['TEXT'],a['UPDATE'],a['CODE']]
return(temp)
def getname_onlydata(a):
temp=[]
if type(a)==list:
for b in a:
temp += getname_onlydata(b)
if type(a)==dict:
if 'nodes' in a.keys():
temp = getname_onlydata(a['nodes'])
else:
temp = [[a['TEXT'],a['UPDATE'],a['CODE']]]
return(temp)
def clearfullname(lists):
out=[]
for i in lists:
if type(i[-1])==list:
for j in i[-1]:
if type(j)==list:
j1=i[:-1]+j
out.append(j1)
else:
out.append(i)
return(out)
def getlayers (url):
downlayers=[]
i=0
k=10
while k:
print('getting layers',i)
try:
link=url+'/{}'.format(str(i))
link1 = link+'?f=json'
a=requests.get(link1,headers=head).text
b=json.loads(a)
c=list(b.keys())
if len(c)>0:
i+=1
if 'subLayers' in c :
if b['subLayers'] == []:
downlayers.append([b['name'],link])
print(link1)
else:
k-=1
else :
k-=1
except:
k-=1
continue
return(downlayers)
def getdataids (link):
link1 = link+'/query?f=json&where=1%3D1&returnIdsOnly=true'
t = 3
datalist=[]
while t:
print('geting ids')
try:
a=requests.get(link1,headers=head).text
b=json.loads(a)
if 'objectIds' in list(b.keys()):
datalist = b['objectIds']
print(link1)
t=0
else:
t-=1
except:
t-=1
continue
return (datalist)
def getdatalen (link):
link1 = link+'/query?f=json&where=1%3D1&returnCountOnly=true'
t = 3
datalist=[]
while t:
print('geting datalen')
try:
a=requests.get(link1,headers=head).text
b=json.loads(a)
if 'count' in list(b.keys()):
datalist = b['count']
print(link1)
t=0
else:
t-=1
except:
t-=1
continue
return (datalist)
def downesrijson(url,datalist):
b=[]
for i in range(0,len(datalist),200):
print('getting datajson...'+'\n'+url+'\n'+str(i+200))
section = str(datalist[i:i+200]).replace('[','').replace(']','')
downurl = url+'/query?f=json&objectIds={}&returnGeometry=true&outFields=*'.format(section)
t=3
while t:
try:
a=requests.get(downurl,headers=head).text
if i == 0:
b=json.loads(a)
if 'features' in list(b.keys()):
t=0
else:
t-=1
elif i>0:
b1=json.loads(a)
if 'features' in list(b1.keys()):
b['features']+=b1['features']
t=0
else:
t-=1
except:
t-=1
continue
return (b)
if 'datalist.json' not in os.listdir():
a = requests.get(alllisturl,headers=head).text
b=a[a.index('['):-1]
b=b[:b.index('var')]
b=b.replace('\t','')
b=[i for i in b.splitlines() if '//'not in i[:6]]
b= ''.join(b)
b=b.replace(',]',']')
alllist =json.loads(b[:-1])
datalist1 = getname(alllist)
datalist = clearfullname(clearfullname(clearfullname(clearfullname(datalist1))))
with open ('datalist.json','w',encoding='utf-8') as f:
json.dump(datalist,f,ensure_ascii=False)
f.close()
elif 'datalist.json' in os.listdir():
with open ('datalist.json','r',encoding='utf-8') as f:
datalist = json.load(f)
f.close()
#namelevel1 =[i[0] for i in datalist]
#namelevel2 = [j[0] for i in datalist for j in i[1] if type(j)==list]
#namelevel3 = [k[0] for i in datalist for j in i[1] for k in j[1] if type(k)==list]
#namelevel4 = [l[0] for i in datalist for j in i[1] for k in j[1] if type(k)==list for l in k[1] if type(l)==list]
if '下载列表.json' not in os.listdir():
alllayerslist=[]
for i in datalist:
tempdict ={}
tempdict['数据名'] = i[0:-2]
tempdict['更新时间'] = i[-2]
tempdict['数据连接'] = i[-1]
layer = getlayers (i[-1])
layers =[]
for j in layer:
tempd = {}
tempd['层名'] = j[0]
tempd['连接'] = j[1]
tempd['数据量'] = getdatalen (j[1])
layers.append(tempd)
tempdict['下载层'] = layers
alllayerslist.append(tempdict)
#修改重复的层名
for i in alllayerslist:
names = [j['层名'] for j in i['下载层']]
for k,l in enumerate(names):
if names.count(l)>1:
i['下载层'][k]['层名']+=i['下载层'][k]['连接'].split('/')[-1]
with open ('下载列表.json','w',encoding='utf-8') as f:
json.dump(alllayerslist,f,ensure_ascii=False)
f.close()
elif '下载列表.json' in os.listdir():
with open ('下载列表.json','r',encoding='utf-8') as f:
alllayerslist = json.load(f)
f.close()
for i in alllayerslist:
path = './'+'/'.join(i['数据名'][:-1]).replace(':','_')+'/'
filedir = i['数据名'][-1].replace(':','_')+'/'
if not os.path.isdir(path+filedir):
os.makedirs(path+filedir)
for j in i['下载层']:
name = j['层名'].replace(':','_')+'.json'
if os.path.isfile(filedir+name):
shutil.move( filedir+name, path+filedir+name)
shutil.rmtree( filedir)
elif os.path.isfile(filedir.replace('/','')+name):
shutil.move(filedir.replace('/','')+name, path+filedir+name)
elif not os.path.isfile(path+filedir+name):
if type(j['数据量'])==int and 0<j['数据量'] :
downurl =j['连接']
downlist = getdataids(downurl)
datajson = downesrijson(downurl,downlist)
with open (path+filedir+name,'w',encoding='utf-8') as f:
json.dump(datajson,f,ensure_ascii=False)
f.close()Json是网页数据的一类重要格式,对于使用GIS的规划工作者,最常见的两类是EsriJson和GeoJson。然而,这两类Json格式的数据冗余较大,国内的极海提出了新的数据格式,虽然网络传输便捷但不能直接使用arcgis或Qgis进行转换使用。
对付非通用格式的json数据,要花一点功夫,以下是我用python编写的极海Json转换代码,希望能够帮到您。
import os,json,time,requests
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
from shapely import geometry
choose = input('转换文件夹内json选1,单个直接输入需要转shp的json名称,不带后缀名:')
def transjsontoshp(name):
try:
with open (name+'.json','r',encoding='utf8')as f:
jasondata = json.load(f)
f.close()
except Exception as Argument:
print (Argument,'\n ......try:gbk')
with open (name+'.json','r',encoding='gbk')as f:
jasondata = json.load(f)
f.close()
listdata =[]
for i in jasondata['data']['features']:
if 'geom' in i.keys() and type( i['geom'])==dict:
listdata .append( {**{'id':i['id']},**i['attrs'],**i['geom']})
elif 'geom' in i.keys() and type( i['geom'])==list:
listdata .append({**{'id':i['id']},**i['attrs'],**{'m':[i['geom']]}})
pddata = pd.DataFrame(listdata)
if 'Point' in jasondata['data']['geometryType']:
pddata['geometry']= [geometry.MultiPoint([geometry.Point(i) for i in j]) for j in pddata['m']]
elif 'Polyline' in jasondata['data']['geometryType']:
pddata['geometry']= [geometry.MultiLineString([geometry.LineString(i) for i in j]) for j in pddata['m']]
elif 'Polygon' in jasondata['data']['geometryType']:
pddata['geometry']= [geometry.MultiPolygon([geometry.Polygon(i) for j in k for i in j]) for k in pddata['m']]
pddata.drop(['m'],axis=1,inplace= True)
gpddata = gpd.GeoDataFrame(pddata)
try:
gpddata.to_file(name+'.shp',driver='ESRI Shapefile',encoding='gbk')
except:
gpddata.to_file(name+'geo.json',driver='GeoJSON',encoding='utf-8')
if choose == '1':
files = [i.split('.json')[0] for i in os.listdir() if '.json'in i]
for f in files:
transjsontoshp(f)
else:
name = choose
transjsontoshp(name)